분류형 Data만 가져오는 간단한 방법 (How to Identify the columns that are categorical in nature)
2019. 10. 3. 13:05ㆍData Science
Data는 크게 두가지 분류로 나눌수 있습니다.
수치형의 Data와 분류형의 Data
Numerical vs Categorical
이렇게 나누는 이유는 분류에 따라서 Data를 전처리하고 분석하는 방법이 상이하기 때문입니다.
금번 Post에는 위 두가지 Data가 스프레드시트 즉, Table형태로 혼재되어 있는 일반적인 Dataset에서
쉽게 Categorical Data 즉, 분류형 자료만 어떻게 분리해서 가져오는지 간단히 Posting 하겠습니다.
1. df.dtypes (Pandas Dataframe이름을 df라고 가정하고 dtypes 매서드를 처보면 아래와 같은 결과가 나옵니다.)
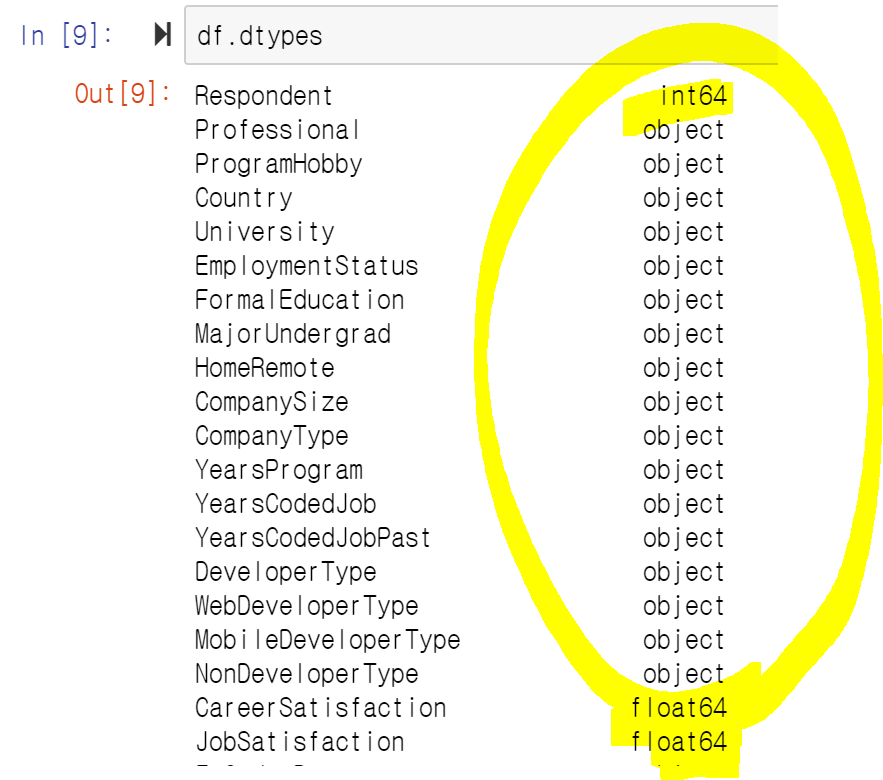
위와 같이 int64 혹은 float64라고 써져있는 것은 문자 자체가 의미하는 것과 같이 수치형 자료입니다.
그외에 object로 나와있는 열은 수치형이 아니기 때문에 분류형이 겠네요.
(물론 예외도 있을수 있습니다. 그냥 의미없는 빈 열일수도 있고요.)
2. 그러면 어떻게 type이 object인 열만 별도의 변수로 따로 가져올수 있을까요?
select_dtypes 라는 매서드를 사용해서 처리하면 되겠습니다.
obj_df = df.select_dtypes(include = ['object']).copy()위와 같이 include = ['자료형 이름'] 을 넣어주고 copy를 하면 됩니다.
또 기대를 저버리지 않고 한줄로 처리할수 있게 해주네요.
기특한 녀석입니다.
'Data Science' 카테고리의 다른 글
| Epoch 과 Batch Size , Iterations 는 머냐? (3) | 2020.04.05 |
|---|---|
| Data 파이프 라인 : ETL vs ELT (0) | 2019.10.27 |
| Missing Value에 대응하는 방법 1. Remove Value - (0) | 2019.09.29 |
| Dataset 으로 무언가 시작하려고 할 때 반드시 체크 해야 되는 5가지 (0) | 2019.09.25 |
| JDBC 와 ODBC의 차이점은 무엇인가? (0) | 2019.09.25 |