2019. 9. 15. 10:41ㆍProgramming Tutorial/Python
Pandas DataFrame에서 특정 행/열을 선택하는 방법은 여러가지가 있습니다.
단연코 Pandas를 사용하면서 이러한 선택의 기로에 많이 놓이게 됩니다. 어떤 방법을 써야될지 혼동이 오는 경우가 참 많죠.
" 역시 반복 밖에 없나봅니다."
자 시작해보겠습니다.
일단 방법은 크게 2가지입니다.
1. 행번호(row number)로 선택하는 방법 (.iloc)
2. label이나 조건표현으로 선택하는 방법 (.loc)
1. 행번호(row number)로 선택하는 방법(.iloc)
조금 혼동이 있을수 있을수 있어 간단하게 다시 표현하면
" 행이든 열이든 숫자로 location을 나타내서 Selecting or indexing 하는 방법입니다."
상상을 조금 해봅시다. row number가 0부터 전체 row 수까지 있죠.
data.shape[0] 하면 data라는 이름의 data frame의 전체 row수를 출력 가능합니다.
즉, .iloc는 이 번호로 특정 data를 선택할수 있도록 해주는 것이죠.
물론 열도 마찬가지 입니다. (범위가 0부터 data.shape[1] 이겠네요)
하지만 어찌뎃건 문자로 서술하는 것은 설명하는 사람이나 보는 사람이나 혼동을 야기할 것입니다.
코드로 예시를 보겠습니다.
data.iloc[0] # data의 첫번째 행만
data.iloc[1] # 두번째 행만
data.iloc[-1] # 마지막 행만
# Columns:
data.iloc[:,0] # 첫번째 열만
data.iloc[:,1] # 두번째 열만
data.iloc[:,-1] # 마지막 열만행이든, 열을 하나만 선택하는 예시였습니다.
역시 숫자만 사용했군요. 이제 여러 행/열을 선택하는 예시를 봅시다.
data.iloc[0:5] # 첫 5개행만
data.iloc[:, 0:2] # 첫 2개열만
data.iloc[[0,3,6,24], [0,5,6]] # 1st, 4th, 7th, 25th 행과 + 1st 6th 7th 열만
data.iloc[0:5, 5:8] # 첫 5개 행과 5th, 6th, 7th 열만
.iloc을 사용할때는 2가지를 기억하셔야 합니다.
1. 어떻게 선택하느냐에 따라 Series로 값이 반환될수도 있고 DataFrame으로 반환될수도 있습니다.
Return값이 어떤 형식인지는 이후 코드르 이어감에 있어서 명확히 알아야 되는 항목이겠죠.
왜 인지는 .. 굳이 설명 안해도 되겠죠?.
( ex, 행하나만 선택했다고 상상해보세요. 이러한 케이스와 비슷할 경우 어떤 타입으로 반환될지도 )
2. 여러개의 행과 열을 선택할 경우에 예시에서도 보셨겠지만 예를 들어
[1:5]이면 1,2,3,4까지이고, 5가 포함되지 않는다는 걸 헷갈리시면 안됩니다.
사실 iloc는 잘 사용되진 않습니다. 알고 있으면 유용하겠지만요.
2. label이나 조건표현으로 선택하는 방법 (.loc)
2.1 Label과 인덱스의 활용을 통한 .loc

위와 같은 Data가 있다고 생각해봅시다.
last_name에 Andrade와 Veness로 이름되어 있는 행을 선택하려 한다고 생각해보자구요.
.loc를 이용하면 아래와 같이 간단하게 해결할수 있습니다.
data.loc['Andrade'] # Andrade 행만 선택
data.loc[['Andrade','Veness']] # Andrade와 Veness 둘다 선택
하지만 또 여기서 잊지 말아야 할게 있죠.
위의 예시중 첫번째는 series를 반환한다는 거고 두번째는 dataframe을 반환한다는 것.
같은 방법으로 열도 가능합니다. 행/열 동시에 label로 선택하는 예시를 잠시 볼까요?
data.loc[['Andreade','Veness'],['first_name', 'address', 'city']]요로케 하면 되겠네요.
아하... 그런데 저렇게 일일이 다 타이핑 치기가 귀찮네요..
어쩌죠?
...
이미 좋은 방법을 알고 계실 겁니다 .
아래와 같이 범위표현도 가능하다는 것을요.
data.loc[['Andrade', 'Veness'], 'city':'email']
특정 숫자로 구별가능하도록 한 id정보가 있는 column이 있다고 상상해봅시다.
그럼 아래와 같이 indexing도 가능합니다.
# Change the index to be based on the 'id' column
data.set_index('id', inplace=True)
# select the row with 'id' = 487
data.loc[487]data.loc[487]의 결과는 당연히 data.iloc[487]과는 다를 거라는거 이해하시죠?
2.2 참/거짓, logical index 과 .loc 활용
가정 : data의 first_name 열이 'Antonio'라는 행을 선택하고 싶다??
위 가정에 대해서 생각해봅시다.
pandas와 기본문법을 활용해서 조건식을 만들어주면 되겠구나 하고 언뜻 생각이드네요.
그냥 바로 아래 예시로 넘어갑시다.
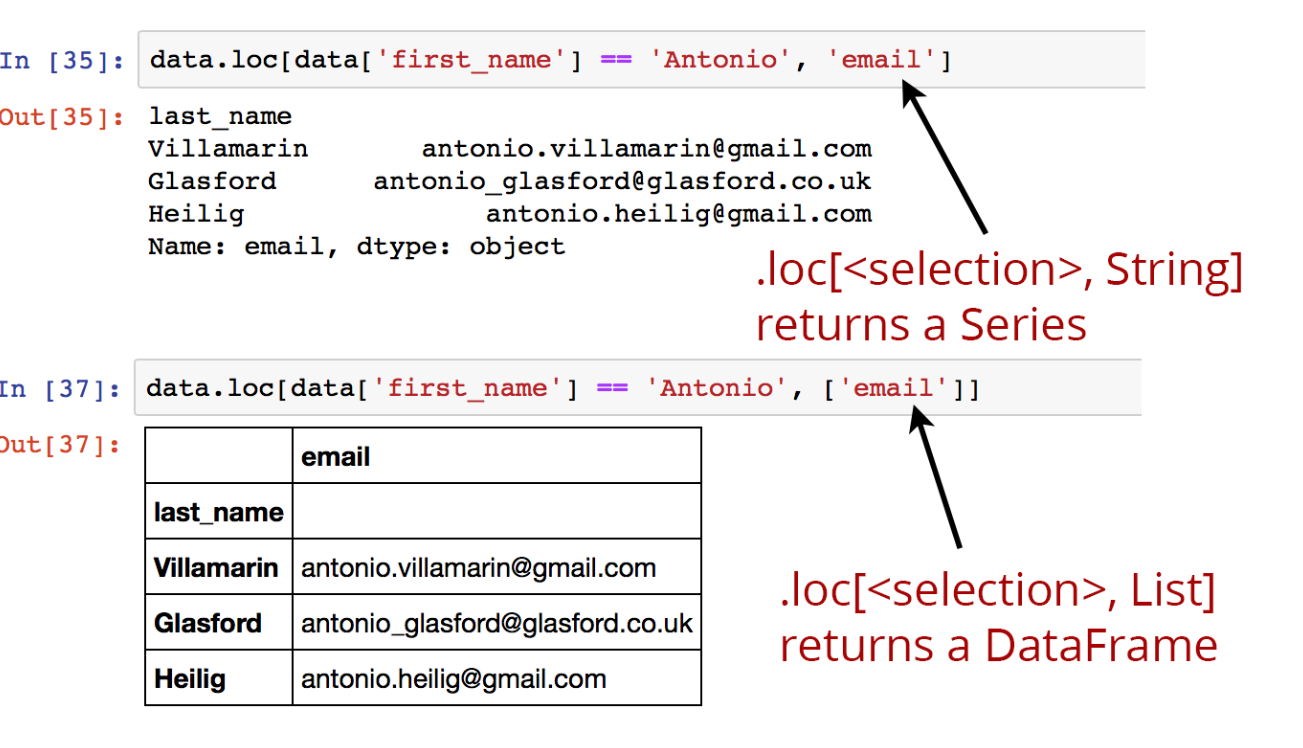
data[data['first_name'] == 'Antonio']간단하기 그지 없네요.
아하 그런데 저 조건의 행에 특정 열만 선택할려면 어찌....
이것도 이미 우리는 알고 있죠?
data[data['first_name'] == 'Antonio', 'email']
요로케 email 열만 조건에 맞게 출력되도록요.
물론 이미 익힌 방법으로 여러 열을 표시할수도 있겠지만 여기서 하나 짚고 넘어갈게 있습니다.
바로 위 예시와 같이 실행하면 결과 형식은??
네. 당연히 series로 나출력되겠네요.
형식이 자꾸 바뀌어서 불편하다 나는 그냥 출력이 그대로 Dataframe 형식이였으면 좋을것 같다. 이런 경우는 어찌해야 되까요?
네 방법이 없는 건 아닙니다. 간단히 반환형식이 바뀌게 할수 있죠 아래와 같이요.
data[data['first_name'] == 'Antonio', ['email']]
이것 외에도 다양하고 복합적인 활용이 있을 것 같습니다만 금번 포스트는 요로케 서두없이 서둘러 마무리하도록 하겠습니다.
posting 할수록 글실력이 늘어야 되는데 늘지 않네요.
다음번 포스팅에는 급한 마음을 가지지 않고 퀄리티를 좀 더 높여보도록 하겠습니다.
'Programming Tutorial > Python' 카테고리의 다른 글
| time series decomposition에 대해서 (1) | 2022.10.08 |
|---|---|
| pandas.DataFrame.reset_index 간단 사용법 1 (0) | 2019.09.24 |
| 정규표현식(RegEx)의 활용 1. (contains와 그 flags 활용) (0) | 2019.09.02 |
| 아나콘다 설치해보자~ how to install Anaconda on your computer (0) | 2019.08.29 |
| 다른 .py파일을 import 하는 방법과 __name__의 정체 (1) | 2019.08.17 |